Generating Art Using a Conditional Generative Adversarial Network with Keras

In this article, I will be describing how to build a conditional DCGAN (deep convolutional generative adversarial network) using the Keras library, and how to train this model on images of classical and modern paintings downloaded from WikiArt.org.
Contents
Introduction
Generative Adversarial Networks (GANs) have been around only since 2014, but have already become incredibly popular and have been used for a broad range of applications. Probably the most straightforward use case for GANs is generation of images similar to those in the training set - which can be composed of virtually anything, from simple handwritten digits to human faces and Pokémons. GANs are notorious for being relatively hard to train, and while training them, one can often feel more like an artist than an engineer. Why then not become a real artist by training a GAN to paint some fancy pieces of art?
The DCGAN we are going to build will be conditional, meaning that we will be able to generate not just any “random” painting, but a painting in the style of the art movement we specify (such as Renaissance or Impressionism). The resolution of the resulting images can be more or less arbitrary (I will choose 128x128 pixels).
As for prerequisites, a good knowledge of the Python programming language and the Keras library for machine learning will be useful for understanding the code snippets. Some understanding of GANs would probably come in handy as well, as I will introduce them only briefly. Also, training the GAN with its ~20M parameters requires access to a fairly strong GPU - training in my case took several hours with the NVIDIA V100 GPU in Google Colab Pro.
Resources (dataset and Colab notebook)
The whole training dataset with real paintings (a ZIP file with 21,253 128x128 images split into 8 subfolders representing art movements) is available here. Disclaimer: I do not own the data, I am merely sharing this low-resolution collection of publicly available images under the fair use principle. Please contact me if you feel like your rights have been violated.
The executable Google Colab notebook with the pre-trained model, as well as with the training dataset can be found here (a GPU is accessible for free in Colab).
Description of Training Data
I collected the training dataset from the WikiArt.org database, which includes over 150K pieces of art from famous artists (practically every painting I’ve ever heard of can be found on WikiArt). The Wikiart Retriever script can be used to conveniently download their art. I hand-selected 83 famous painters (including Da Vinci, Rembrandt, Monet, Picasso, Dalí, and, of course, Chaïm Soutine), and then downloaded all of their available works - resulting in a total of 21,253 images.
While WikiArt stores information about the art movements together with the paintings, I did not use it directly: instead, I manually sorted the artists into 8 movements: Renaissance, Baroque, Romanticism, Realism, Impressionism, Post-Impressionism, Expressionism, and Surrealism.
Unfortunately, some photographs (mostly of statues) have found their way into the dataset, but there should be only a handful of them - a bigger problem seems to be the inclusion of some rough drawings and sketches, which I also decided to keep in the dataset.
Here is a batch of images from the final training dataset:

The distribution of images across the categories (movements) is as follows:
- Renaissance: 2,394 images
- Baroque: 2,853 images
- Romanticism: 1,571 images
- Realism: 1,235 images
- Impressionism: 6,599 images
- Post-Impressionism 2,988 images
- Expressionism: 716 images
- Surrealism: 2,897 images
- Total: 21,253 images
A Brief Introduction to GANs
Unconditional (Classical) GANs
The basic principle of training an unconditional GAN is to alternately train two components - a generator (in our case, an “artist” that tries to output a nice novel “painting” from a random noise given as input) and a discriminator (in our case, an “art critic” that takes a “painting” as input and tries to score it with a number between 0 and 1 - with something closer to 1 for a real painting, and something closer to 0 for a “fake painting” from the generator). First, both the generator and the discriminator don’t really know what they are doing, but they keep improving over time, with the generator producing images that resemble the original dataset more and more - which is the goal.
Here is the typical training process: first the discriminator is trained on some real paintings (with a target output of 1), and on some “fake paintings” generated by the generator (with a target output of 0) - which results in the discriminator scoring real paintings as more realistic (output closer to 1) and the generated “fake” paintings as less realistic (output closer to 0). Then we take the generator, plug it right before the discriminator (so that its generated images are fed directly to the discriminator), freeze the weights of the discriminator (so that only the generator is trained), and perform training on some random noise inputs, with the target output of 1 - which results in the generator producing images which will be regarded as more realistic than before by the discriminator. This typically leads to the generated “fake” images being more similar to the original ones from the training dataset.
Conditional GANs
Unconditional GANs are fine when we have an uncategorized dataset - a trained generator simply keeps generating any item that looks like it could have been in the training dataset. However, if we have labels associated with the training data (such as art movements - e.g. Impressionism or Surrealism), we may want to be able to specify (after we train the GAN) what art movement we want to have generated, so that we don’t have to keep generating random art until we find the one belonging to the desired movement. This is done by providing the class label to both the generator and the discriminator, during training and after training as well.
Conditional GANs are very similar to unconditional GANs, only both the generator and the discriminator have a class label added to their inputs. Everything else is done exactly in the same way as in unconditional GANs, only while training, we add the labels of the training data as inputs (the same label goes to the generator as goes to the discriminator), and after the training is complete, we have to specify what class we want to have generated.
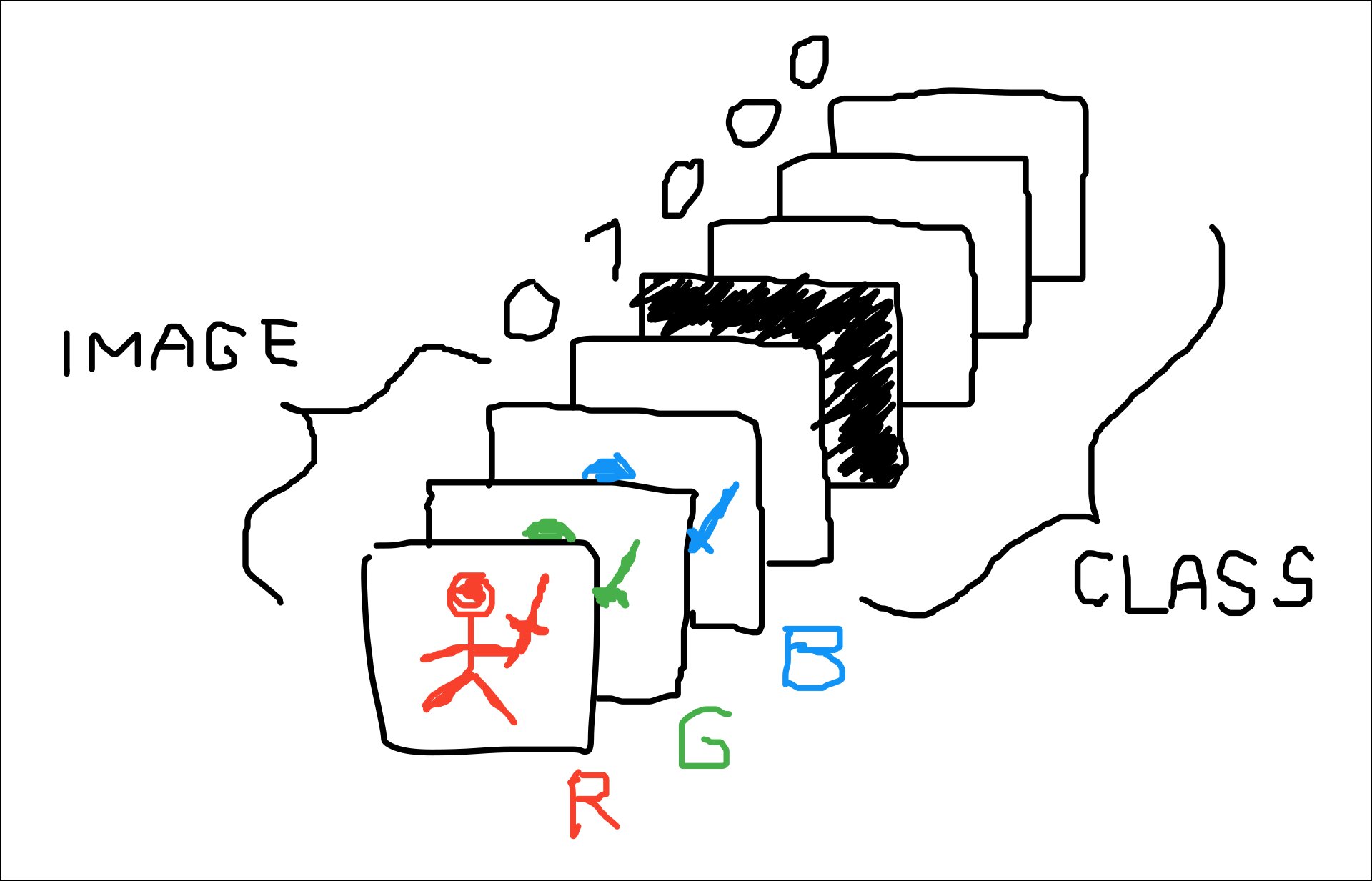
For the generator, its two inputs (noise and one-hot encoded class label) are simply concatenated. For the discriminator, its two inputs (image and one-hot encoded class label) can be concatenated along the channel axis of the image, resulting in a discriminator input shown in the diagram below (in this case, each of the classes takes up an entire channel).
Deep Convolutional GANs
Deep Convolutional GANs, or DCGANs, are a popular architectural convention for designing GANs, as DCGANs have been found to work quite well with many image generation tasks. DCGANs utilize a minimal amount of fully connected (dense) layers, relying instead on transposed convolution layers in the generator to scale up the size of the feature maps (i.e. the “images”) as the signal goes through the model, and on convolution layers in the discriminator to scale down the size of the feature maps.
Several recommendations for designing DCGANs have been stated in the original paper that introduced DCGANs:
- Replace any pooling layers with strided convolutions.
- Use batch normalization.
- Remove fully connected hidden layers for deeper architectures.
- Use the ReLU activation function in the generator for all layers except for the output, for which choose Tanh activation.
- Use the LeakyReLU activation function in the discriminator for all layers.
Building the Conditional DCGAN
We will build our Conditional DCGAN mostly in accordance with the DCGAN guidelines stated above, but with two exceptions: I chose SELU instead of ReLU as the activation function for the generator and replaced the batch normalization layers with layer normalizations (for some reason, the GAN did not learn at all when I tried using batch normalization, possibly of a bug in Keras or TensorFlow).
The generator will start with 1024 filters in the first (lowest) layer, and every following (upper) layer will reduce this number by half as the size of the feature maps increases. On the opposite, the discriminator will start with just a few filters in the input layer, and the number of filters will be increased up to 512 as the feature maps shrink. This is in accordance with the idea that image processing requires many high-level features, but that just a few low-level features are sufficient.
I chose 4 as the size of the filters (kernels). The stride of the convolutions and transposed convolutions will be 2. We will also regularize the discriminator with dropout (randomly dropping 25% of input units). The loss function used will be binary cross-entropy.
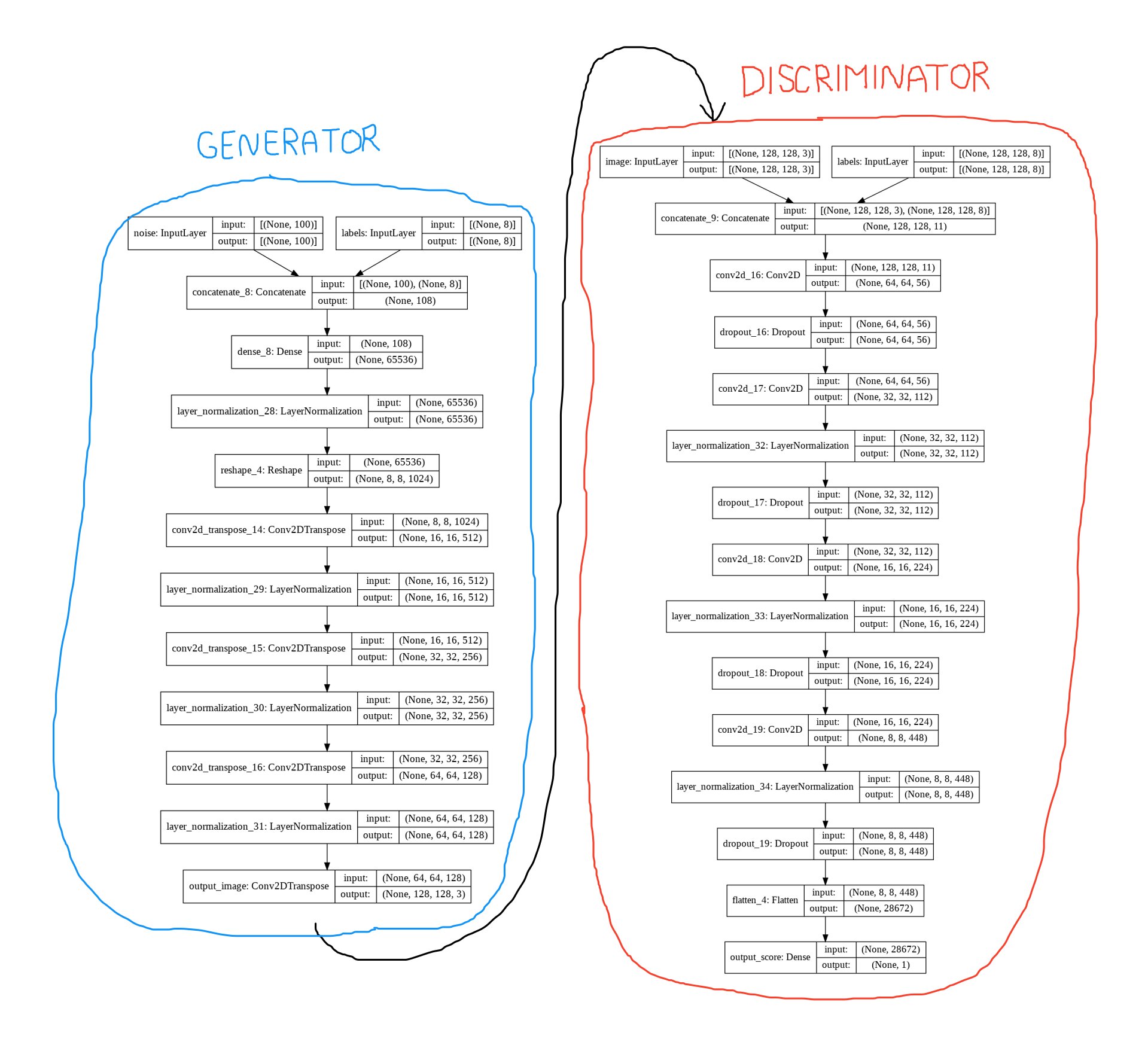
The result will be a generator with 18,293,379 parameters, and a discriminator with 2,941,697 parameters. Our target architecture of the conditional DCGAN can be seen in this diagram:
It’s time to start coding! First, we load the required libraries:
1
2
3
4
5
6
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
import numpy as np
import time
%matplotlib inline
Next, we set some variables with important constants and load the training dataset from its directory (make sure that you have downloaded and extracted the training dataset):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
IMAGE_SIZE = 128
BATCH_SIZE = 32
dataset = keras.preprocessing.image_dataset_from_directory(
'wikiart-paintings-128',
labels='inferred',
label_mode='int',
color_mode="rgb",
batch_size=BATCH_SIZE,
image_size=(IMAGE_SIZE, IMAGE_SIZE),
shuffle=True,
)
N_CLASSES = len(dataset.class_names)
N_CLASSES
Now we can build the generator and the discriminator. First, we separately compile the discriminator, and then also the whole GAN (with the generator plugged before the discriminator).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
CODINGS_SIZE = 100
def build_generator():
# The random noise input
noise = keras.Input(shape=[CODINGS_SIZE], name="noise")
# The class label input
labels = keras.Input(shape=[N_CLASSES], name="labels")
noise_with_labels = tf.keras.layers.concatenate([noise, labels])
x = keras.layers.Dense(8 * 8 * 1024)(noise_with_labels)
x = keras.layers.LayerNormalization()(x)
x = keras.layers.Reshape([8, 8, 1024])(x)
x = keras.layers.Conv2DTranspose(
512, kernel_size=4, strides=2, padding="SAME",
activation="selu")(x)
x = keras.layers.LayerNormalization()(x)
x = keras.layers.Conv2DTranspose(
256, kernel_size=4, strides=2, padding="SAME",
activation="selu")(x)
x = keras.layers.LayerNormalization()(x)
x = keras.layers.Conv2DTranspose(
128, kernel_size=4, strides=2, padding="SAME",
activation="selu")(x)
x = keras.layers.LayerNormalization()(x)
# The generated image
output = keras.layers.Conv2DTranspose(
3, kernel_size=4, strides=2, padding="SAME",
activation='tanh', name="output_image")(x)
return keras.Model([noise, labels], output)
def build_discriminator():
# The generated or real image input
image = keras.Input(
shape=[IMAGE_SIZE, IMAGE_SIZE, 3], name="image")
# The class label input
labels = keras.Input(
shape=[IMAGE_SIZE, IMAGE_SIZE, N_CLASSES], name="labels")
image_with_labels = tf.keras.layers.concatenate([image, labels])
x = keras.layers.Conv2D(
56, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2))(image_with_labels)
x = keras.layers.Dropout(0.25)(x)
x = keras.layers.Conv2D(
112, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2))(x)
x = keras.layers.LayerNormalization()(x)
x = keras.layers.Dropout(0.25)(x)
x = keras.layers.Conv2D(
224, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2))(x)
x = keras.layers.LayerNormalization()(x)
x = keras.layers.Dropout(0.25)(x)
x = keras.layers.Conv2D(
448, kernel_size=4, strides=2, padding="SAME",
activation=keras.layers.LeakyReLU(0.2))(x)
x = keras.layers.LayerNormalization()(x)
x = keras.layers.Dropout(0.25)(x)
x = keras.layers.Flatten()(x)
# The output prediction
output = keras.layers.Dense(
1, activation="sigmoid", name="output_score")(x)
return keras.Model([image, labels], output)
noise = keras.Input(shape=[CODINGS_SIZE])
labels_generator = keras.Input(shape=[N_CLASSES])
generator = build_generator()
generated_image = generator([noise, labels_generator])
labels_discriminator = keras.Input(
shape=[IMAGE_SIZE, IMAGE_SIZE, N_CLASSES])
discriminator = build_discriminator()
discriminator.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.Adam(2e-4, 0.5))
discriminator.trainable = False
validity = discriminator([generated_image, labels_discriminator])
gan = keras.Model(
[noise, labels_generator, labels_discriminator], validity)
gan.compile(
loss="binary_crossentropy",
optimizer=keras.optimizers.Adam(2e-4, 0.5))
Training the Conditional DCGAN
Now we will define the function for training the GAN, as well as some helper functions for encoding the labels and plotting the images.
The train_gan function requires some explanation: While training, we will keep loading a batch of training data from the dataset, along with its class labels. For each loaded batch, we first train the discriminator on a “batch” of “fake paintings” generated by the generator, and then on the loaded batch of real paintings. Next, we train the whole GAN (with the discriminator’s weights frozen) on a “batch” of random noise in order to train the generator. In all of the steps, the input labels of both the generator and the discriminator are set to the class labels of the current batch loaded from the dataset.
Here is the promised code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
def get_labels_generator(y_batch):
"""
One-hot encode the class labels for the generator.
"""
return tf.one_hot(y_batch, N_CLASSES)
def get_labels_discriminator(y_batch):
"""
One-hot encode the class labels for the discriminator.
"""
classes = tf.one_hot(y_batch, N_CLASSES)
classes = tf.reshape(classes, [-1, 1, 1, N_CLASSES])
classes = tf.repeat(classes, IMAGE_SIZE, axis=1)
classes = tf.repeat(classes, IMAGE_SIZE, axis=2)
return classes
def plot_multiple_images(images, n_cols=None):
"""
Display a grid of images.
"""
n_cols = n_cols or len(images)
n_rows = (len(images) - 1) // n_cols + 1
if images.shape[-1] == 1:
images = np.squeeze(images, axis=-1)
plt.figure(figsize=(n_cols*2.7, n_rows*2.7))
for index, image in enumerate(images):
plt.subplot(n_rows, n_cols, index + 1)
plt.imshow(image, cmap="binary")
plt.axis("off")
def train_gan(
gan, generator, discriminator, dataset, batch_size,
codings_size, n_epochs=50, log_every=1):
for epoch in range(n_epochs):
print(f"Epoch {epoch + 1}/{n_epochs}")
gen_loss = 0
disc_loss = 0
n_batches = 0
latest_batch = None
for X_batch, y_batch in dataset:
n_batches += 1
if X_batch.shape[0] != BATCH_SIZE:
continue
latest_batch = X_batch
X_batch = X_batch / 127.5 - 1
# phase 1 - training the discriminator
noise = tf.random.normal(
shape=[batch_size, codings_size])
labels_generator = get_labels_generator(y_batch)
generated_images = generator([noise, labels_generator])
discriminator.trainable = True
labels_discriminator = get_labels_discriminator(y_batch)
disc_loss += discriminator.train_on_batch(
[generated_images, labels_discriminator],
tf.constant([[0.]] * BATCH_SIZE))
discriminator.trainable = True
disc_loss += discriminator.train_on_batch(
[X_batch, labels_discriminator],
tf.constant([[1.]] * BATCH_SIZE))
# phase 2 - training the generator
noise = tf.random.normal(
shape=[batch_size, codings_size])
y2 = tf.constant([[1.]] * batch_size)
discriminator.trainable = False
gen_loss += gan.train_on_batch(
[noise, labels_generator, labels_discriminator], y2)
print(f"Generator/discriminator losses: {gen_loss}/{disc_loss}")
gen_avg_pred = np.mean(discriminator.predict(
[generated_images, labels_discriminator]))
real_avg_pred = np.mean(discriminator.predict(
[latest_batch, labels_discriminator]))
print(f"Generated/real avg predictions: {gen_avg_pred}/{real_avg_pred}")
if (epoch % log_every) == 0:
latest_batch = latest_batch / 127.5 - 1
plot_multiple_images((latest_batch + 1) / 2, 8)
plot_multiple_images((generated_images + 1) / 2, 8)
plt.show()
We are finally ready to train the whole thing!
1
2
3
train_gan(
gan, generator, discriminator, dataset,
BATCH_SIZE, CODINGS_SIZE, n_epochs=100, log_every=1)
Feel free to change the number of epochs to any desired value (I recommend setting it to something ridiculously large and then interrupting the Python kernel once you are satisfied with the results). Be aware that with the size of the networks we have defined, the training process takes at least several hours on an NVIDIA V100 GPU.
Results
In order to play with the trained GAN, we will define a function that allows generating either paintings of randomly selected movements or only paintings of the movement we specify:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
CLASS_NAME_TO_INDEX = {
'baroque': 0,
'expressionism': 1,
'impressionism': 2,
'post-impressionism': 3,
'realism': 4,
'renaissance': 5,
'romanticism': 6,
'surrealism': 7,
}
def generate_images(class_name=None, noise_scaling=0.7):
"""
:param noise_scaling: Scale down the noise so that "more confident"
paintings are generated.
"""
if class_name is None:
classe_indices = list(np.random.randint(0, 8, size=BATCH_SIZE))
labels_generator = get_labels_generator(classe_indices)
else:
class_index = CLASS_NAME_TO_INDEX[class_name]
labels_generator = get_labels_generator(
[class_index] * BATCH_SIZE)
noise = tf.random.normal(
shape=[BATCH_SIZE, CODINGS_SIZE]) * noise_scaling
generated_images = generator([noise, labels_generator])
plot_multiple_images((generated_images + 1) / 2, 8)
Here are some of the generated “paintings”, belonging to randomly selected movements:
1
generate_images()

With our GAN, we have become very abstract artists indeed. When viewed by a person with bad eyesight, from a significant distance, and through a kaleidoscope, the images resemble conventional paintings: the colors are quite convincing and both the high-level composition as well as the low-level structure of the “brush strokes” look about right. However, the depicted objects are problematic, to say the least: persons, houses, or trees can’t really be recognized without tremendous amounts of imagination. On the other hand, some landscapes look nice and personally, I’m reasonably satisfied with the overall amount of surrealism.
Here are only “paintings” in the Renaissance style:
1
generate_images('renaissance')

The images have the typical dark colors of the Renaissance. I believe that the brighter, white-and-black paintings are supposed to be sketches, which are quite common in the Renaissance class of the training dataset.
Baroque:
1
generate_images('baroque')

The fake Baroque “portraits” include depictions of what we can guess to be human figures, some with recognizable attempts of facial features. Other than that, they are quite similar to the Renaissance outputs.
Romanticism:
1
generate_images('romanticism')

Romanticists mostly painted landscapes, as we can tell (with some difficulty) from the generated images.
Realism:
1
generate_images('realism')

Like with Romanticism, the fake Realism “paintings” also include mostly landscapes, which is interesting due to the fact that the Realism part of the training dataset contained also a lot of portraits, and many other kinds of objects (such as flowers) as well. I suspect that collecting more Realism paintings for the training dataset would help significantly here.
Impressionism:
1
generate_images('impressionism')

The Impressionism class is the one with the most data in the training dataset. The generated pictures of flowers are nice and include visible brush strokes, which are typical for Impressionists.
Post-Impressionism:
1
generate_images('post-impressionism')

The style of the Post-Impressionist outputs is quite different from Impressionism, with less visible brush strokes and more complex compositions. In some pictures, there seem to be attempts at depictions of buildings.
Expressionism:
1
generate_images('expressionism')

The Expressionist part of the training dataset includes the lowest number of paintings, the depicted compositions are often very complex and the styles are very artist-specific. Considering this, I think that the generated images are interesting, although completely abstract.
Surrealism:
1
generate_images('surrealism')

The Surrealist part of the training dataset is the most complex one, with bizarre compositions of absolutely unrelated objects. It seems like this was a problem for the GAN, as I don’t really know what’s going on in any of these generated pictures (besides a few candidates for natural sceneries).
Things start to get very interesting once we start to cherry-pick the best images. Note that some of the following paintings were obtained using a little bit simplified, unconditional version of the GAN (which I have not discussed in this article but which could be approximated by putting all of the paintings from the training dataset into a single class).
For example, when looking at some generated images, I discovered the portrait of your great-grandfather:

Here is a mysterious masked woman:

Something that Picasso would have painted if he were a deep convolutional generator:

A Renaissance portrait:

A figure in a blanket:

Let’s move to more complicated compositions. This could be called something like The Removal of The Body of Jesus From the Cross:

Storm on the sea, after a gap formed in the clouds:

Some expressionist trees:

Flowers come out quite nicely:

More flowers:

Even more flowers:

And some extra flowers:

Similarly to flowers, landscapes aren’t bad either:

Another example:

Or another one:

And, to conclude the results section, one final landscape:

Conclusion and final thoughts
Training GANs on art datasets is fun and satisfying. As many of the paintings are in the public domain and the task is difficult enough, I would not be surprised to see art generation become a popular machine learning benchmark for image generation methods.
Obviously, the results shown in this article are not ideal and there is significant room for improvement. I recommend checking out this GitHub repository, which showcases an unconditional DCGAN trained on various categories of classical paintings, such as landscapes and portraits (and even nude portraits!). I took inspiration from this repository for this project, but I obtained worse results - as an excuse, I have to mention that I chose a more difficult task because of the very broad dataset composed of paintings of various styles and categories of objects. In order to improve my results, it is possible that increasing the size of the training dataset, as well as filtering out unwanted items such as photographs and sketches, would help. One could also couple this approach with increasing the number of parameters of the neural networks to obtain a more powerful model, and also the resolution of the resulting images could be increased somehow.
Last but not least, I am sure that this task would be better solved by some of the latest methods and architectures for training GANs, instead of a simple DCGAN. I think that the GANs Specialization by deeplearning.ai at Coursera would be a great place to delve deeper into GANs.
I hope you enjoyed this article. Please reach me in case you have found any issues or if you have ideas for improvement.
